
This is Blog #1 in a 3 Part Blog Series On HL7 and Healthcare Data Interoperability
What is HL7?
If you’ve worked with healthcare data, chances are you’ve heard of HL7v2. To give some background for those who aren’t familiar, HL7v2 is a messaging standard that is used to electronically exchange clinical data between systems of a healthcare organization. It has been adopted by healthcare institutions across the world to transmit large volumes of healthcare data in real-time. While this standard is great for exchanging information, it was not designed with analytics in mind. In it’s raw form, HL7v2 data is difficult to analyze and requires a significant amount of pre-processing. This poses an issue for healthcare organizations who want to perform queries on large volumes of data to quickly gain insights.
Smolder Solves the Problem
The solution to ingest and perform ETL on large volumes of HL7v2 data is to use Smolder within Databricks.
Smolder is an open-source library that makes it very easy to parse HL7v2 data in Spark. It enables you to load HL7 messages directly into Spark DataFrames and integrates seamlessly into Delta Lake.
There are a few prerequisite steps that need to be taken in order to get Smolder set up on your cluster so you can start parsing HL7v2 data. We’re going to make this process as simple as possible so you can start working with your data sooner.
Smolder Library Jar File for Spark
First, the library needs to be compiled as a JAR file. We’ve gone ahead and done this step for you. All you need to do is download the JAR file from here.
Databricks Workspace
Start a cluster in Databricks as per your requirements. Once the cluster is running, navigate to the “Library” tab and select the “Install new” button. Simply click on “Drop JAR here” and select the JAR file to install it on the cluster. You can also just drag and drop the JAR file.
Now that Smolder is installed on the cluster, we can start using it to parse our .hl7 files. For instance, we have an HL7 file consisting of 400 ADT_A01 (Patient Admit/Visit) messages that was uploaded to FileStore via File → Upload data. The HL7 file was obtained from Simulated Hospital and can be downloaded here.
We can simply read in our HL7 file via the Spark DataFrameReader API and specify a line separator in order to distinguish between messages. However, looking at the schema our values are still strings that we need to separate into two columns: Message and Segments.
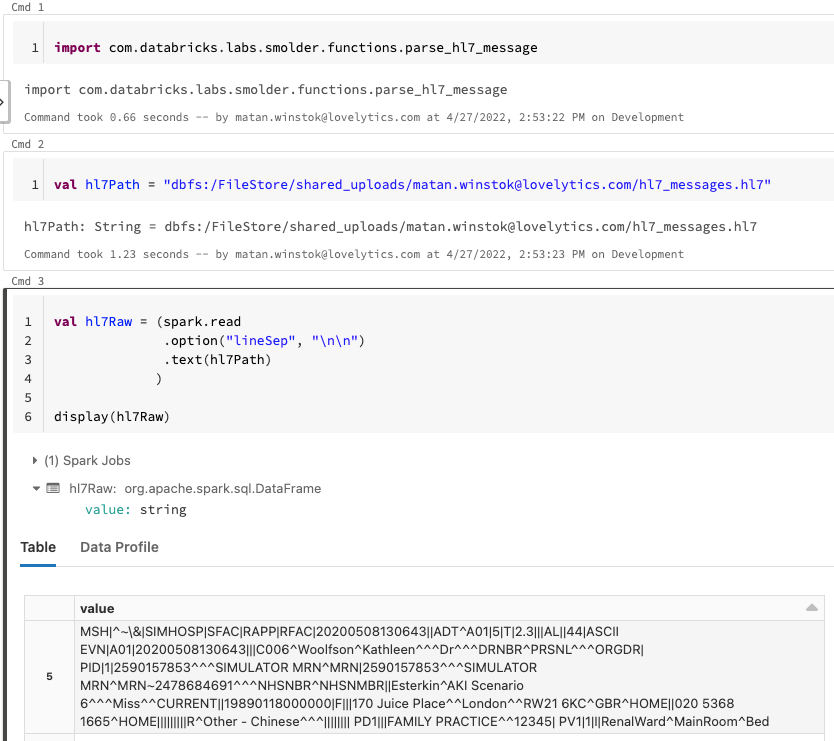
Smolder makes this very easy with the “parse_hl7_message” function. We see in the image below that we have now parsed our HL7 data and separated the raw data into messages and segments.
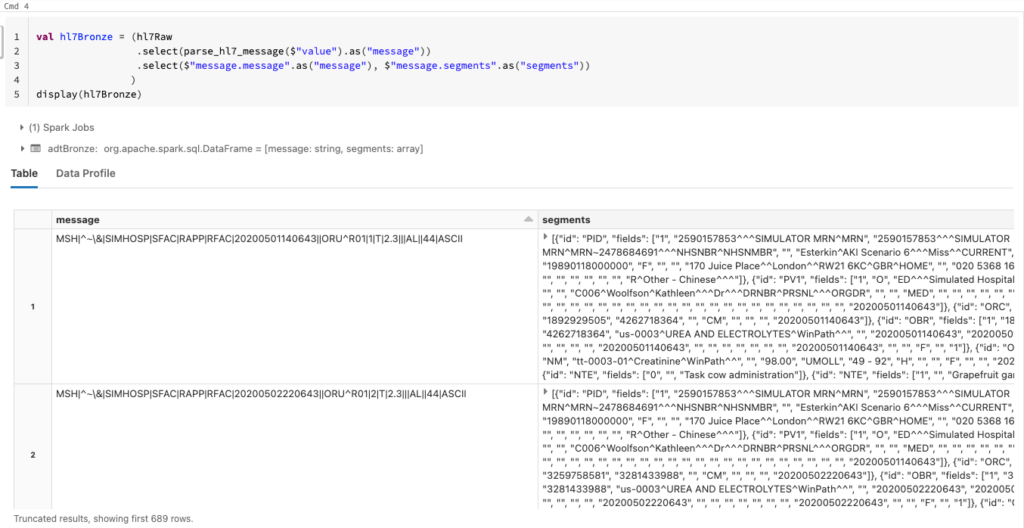
From here, now that we’ve parsed our data we can begin processing it to build out our ETL pipelines which we have outlined in the next blog. Click here to read Blog #2 in the 3-part series.
Lovelytics is a preferred partner of Databricks and has helped many clients install and configure their Databricks instances. To learn more please visit us at www.lovelytics.com/partners/databricks or connect with us via email at [email protected]
Healthcare Interoperability is a focus for Lovelytics and Databricks. Please join us at the Databricks AI Summit on June 27-30 2022 in San Francisco to see Healthcare Interoperability in action. Click here to register to attend.