In this article, we explain how to build a modern data architecture with AWS. Additionally, we describe the ecosystem of services it offers for Data Analytics projects. We cover each stage: storage, ingestion, transformation, exploitation, and data visualization.
How to Build Modern Data Architectures with AWS?
A data architecture provides the information a business needs to make data-driven decisions. Shaping these types of architectures involves creating a network of services and assigning a specific purpose to each.
When building any data solution, it’s important to define two key aspects:
1) Which data we will work with: It’s essential to be clear about the available data and analyze it from three perspectives:
- Data Structure: whether it is structured (like tables in relational databases), semi-structured (those with a flexible structure, like JSON or XML files), or unstructured (videos, images, social media comments, etc.)
- Access Frequency: defining how often we’ll access the data. Keep in mind that higher frequency means higher costs and vice versa.
- Data Volume: this relates to quantity. Remember that higher volume generally leads to higher latency and vice versa.
2) Who will use the data and how: This points to the profile of the data user. They could be data science teams, architecture teams, engineering, visualization teams, Data Product Managers, Business Sponsors, governance areas, etc. Anticipating this when designing the solution is essential since each has a different level of knowledge regarding data use.
Once these aspects are defined, it will be time to choose the AWS service that best suits these characteristics.
What is the AWS Service Ecosystem?
AWS is a cloud provider that enables the selection of specific services to address specific business needs.
We refer to it as a service ecosystem because each service can be connected to others based on business requirements. The services are grouped according to the role they play at each stage of the data analytics process:
- Security.
- Storage.
- Ingestion.
- Transformation.
- Exploitation.

In the following image, you can see a map of AWS’s data analytics service ecosystem.

What Are the Data Storage Services in AWS?
Let’s start at the beginning: where and how to store data. S3 (Simple Storage Service) is the primary storage service in the data lake, and its main features include:
- Durability: The data we store here is very unlikely to be lost. The probability of this happening is extremely low.
- Availability: It’s designed to offer 99.99% availability, making data readily accessible.
- Ease of Use: It has simple APIs and is easy to configure.
- Scalability: We can store all types of files and independently scale storage and compute capacity, virtually without limit.
- Integration with Other AWS Services: It integrates easily with other services.
As we’ve explained in other articles, a data lake only has value when we make use of it. The goal shouldn’t just be to store data — we risk turning it into a data swamp. Instead, we need to ensure the business uses the data for specific purposes.
For example, in this video, we demonstrate how the AWS console works and how to set up buckets in S3.
What Are the Data Ingestion Services in AWS?
Once S3 is set up, it’s time to start filling it. At this stage, it’s essential to define the type of ingestion we’ll perform, taking into account the following aspects:
- Data Source: The three most common sources are files, databases, and streams. This distinction matters, as ingesting a flat file differs from a stream.
- Update Frequency: We can choose from real-time, batch, micro-batch, or daily updates.
- Volume: This is associated with the data source, with sizes ranging from terabytes (TB) to megabytes (MB) or gigabytes (GB).
- Load Type: This can be historical or incremental.
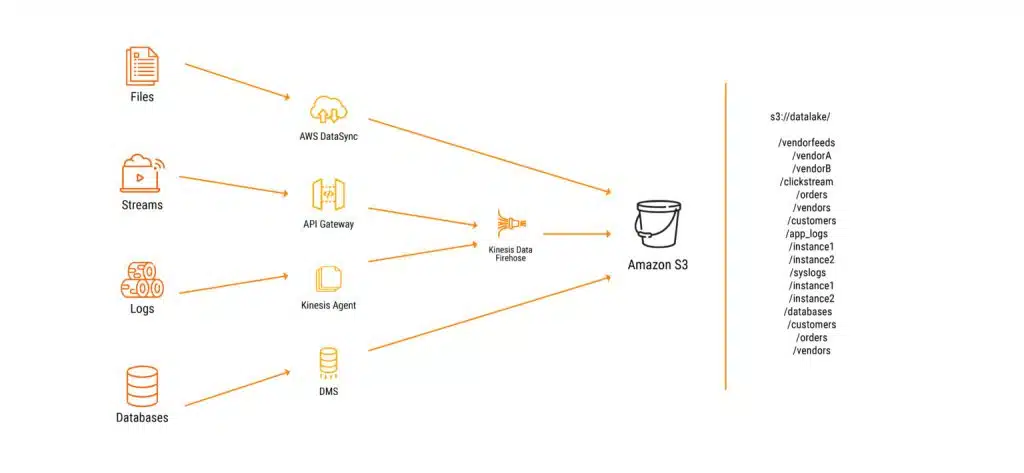
Services for Database Ingestion
AWS offers the following:
Amazon Database Migration Service (AWS DMS): This service securely migrates and/or replicates data from various sources (databases, data warehouses, NoSQL databases) to the AWS cloud. Originally designed to move on-premises databases to the cloud, AWS DMS now also allows data migration to S3 alongside cloud migration, effectively moving data from the database to S3.
AWS Schema Conversion Tool (AWS SCT): Converts database and data warehouse schemas from commercial engines to open-source engines or native AWS services, such as Amazon Aurora and Redshift.
Services for File Ingestion
Several services are available depending on the type of synchronization and file types involved. The most important for this stage are:
AWS DataSync: Synchronizes an on-premises network drive with S3.
AWS Transfer – SFTP
AWS Snowball/Snowmobile: Used when migrating terabytes of data. AWS provides devices that connect to your network to download files, which AWS then transports to its facility and loads into your bucket.
For optimizing cloud transfers at this stage, we can use: S3 multi-part upload, S3 transfer acceleration, and AWS Direct Connect.
Services for Real-Time Data Ingestion
Amazon Kinesis, this service includes three components:
Data Streams: Captures streaming data that multiple consumers can read. It allows for real-time alerting by capturing data for later processing.
Firehose: Functions as a plug-and-play option, making it easier to use but less flexible. It provides temporary storage by buffering streaming records before writing them to a single destination for more efficient storage, which Data Streams cannot do.
Analytics: Complements the previous two. It uses SQL to create time windows on Streams.
For example, in this video, we demonstrate how to set up Kinesis from the AWS console.
What Are the Data Transformation Services in AWS?
After selecting storage and ingesting data, it’s time to start working on data transformations. In this stage, the main services we can use are Amazon Glue and Amazon Lambda.
Amazon Glue: AWS’s primary serverless solution for ETL (or ELT in a data lake). It has three main components:
- AWS Glue Data Catalog: A place to store metadata.
- Glue ETL: Allows data transformations via jobs using Python or PySpark code.
- Crawlers: After storing data in S3, crawlers automatically keep metadata in the AWS Glue Data Catalog updated. Following ingestion, crawlers scan S3 directories, infer information, and update the metadata catalog.
For ETL processes, Glue can auto-generate code through visual code generation (Glue Studio) using open languages like Python/Scala and Apache Spark. Once the script is ready, Glue enables us to execute it, monitor it, or schedule its execution. Additionally, this service lets us create workflows, meaning we can combine scripts or jobs into a larger, orchestrated process.
For example, in this video, we demonstrate how to use AWS Glue from the AWS console.
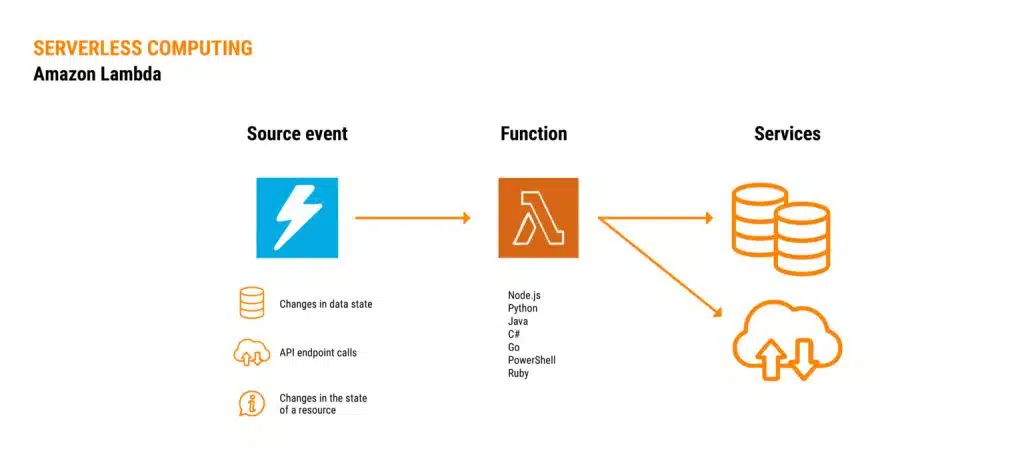
Amazon Lambda is a broad-reaching service that isn’t exclusively focused on analytics.
To use it, we need to define a function in a programming language, which will be triggered based on a source event (such as a state change in a database, API calls, or changes in a resource’s state).
Lambda is serverless and highly flexible, enabling it to handle almost any use case.
Data Exploitation Services in AWS
After completing the previous stages, it’s time to start analyzing the data. AWS provides two main services for this purpose:
Amazon Athena: This service allows you to run interactive queries, simplifying data analysis directly from S3 (the data lake) through the AWS Glue Data Catalog. It’s serverless, cost-effective (pay-as-you-go at USD 5 per TB), and accessible to anyone familiar with SQL (ANSI SQL).
For example, in this video, we demonstrate how to use Amazon Athena from the AWS console.
Amazon Redshift: AWS’s data warehouse service. At this stage, it’s essential to ensure data quality. Redshift uses parallel processing (MPP) and ANSI SQL. While it’s not serverless, it is fully managed by AWS, offers guaranteed scalability, and integrates with the data lake.
Data Visualization Services in AWS
Amazon QuickSight: A traditional BI tool for generating charts, maps, etc. It’s serverless, customizable, and embeddable (allowing dashboards to be integrated into your own platform). QuickSight includes machine learning features, such as automatic narratives, predictions, anomaly detection, and machine learning.
SageMaker: A suite of services for machine learning and AI projects, covering all stages from data preparation to model selection, parameterization, and deployment.
Conclusions
Modern data architectures are built as a network of services rather than monolithic structures. They should be viewed as data analytics solutions composed of various components with specific purposes.
We need to shift the traditional paradigm: previously, we modeled the data, then loaded it, and then analyzed it—a sequence typical of a traditional data warehouse. Now, with data lakes, the order has changed: we load, analyze as needed, and model what makes sense (from ETL to ELT).
Key principles:
- Good Data Governance: With diverse sources, specialized services, and many derived data products, strong governance is more critical than ever.
- Simplicity: When working with these architectures, minimize complexity, scale it as needed, and prioritize flexibility and maintenance.
- Long-term Design, Short-term Implementation: Design with long-term goals in mind but implement for short-term needs. Identify current business needs that align with the long-term design to deliver immediate value and test the long-term architecture.
—
This article was originally written in Spanish and translated into English with GPT.
—
* This content was originally published on Datalytics.com. Datalytics and Lovelytics merged in January 2025.